|
In a previous post, I showed you how to render a PDF documentation (.pdf) with an extra image prepended to the whole PDF document using PDF Rewriter. In this post, I'll show how to render a PDF documentation with an additional PDF page appended as a back-cover. This PDF backcover can not be done by PDF Rewritter, as an Adobe staff confirmed PDF Rewriter (used Apache FOP 0.95) has yet to support merging PDF files. **UPDATE: External links to pdf-files on http-servers and https-servers supported since Apache FOP 1.1. For merging PDF files, I'll be using a Java PDF library - pdfbox. For this, we need pdfbox app OSGi bundle/jar (1.8.2 as of this writing or the latest version) deployed in the Felix OSGi container so we can develop a .jsp to call into the API for merging PDFs. So get the library ready in your CQ environment with these steps:
Note: If you ever need to develop using CRXDE Lite to call into pdfbox library, you want to put the same OSGi bundle/jar to CRXDE's classpath in case you'd use CRXDE Lite as you development environment in the future. You can achieve this by putting a copy of downloaded pdfbox-app-1.8.2.jar to under /etc/crxde/profiles/default/libs/ in CRX via WebDav access (e.g., WebDav URL http://localhost:4502/crx/repository/crx.defult) Once the PDFBox API is deployed into CQ, then come up with a JSP code that will render page with .download.pdf extension. At the high level, we want the request to pages with .download.pdf be handled by our custom JSP code that we'll explain further below. In the JSP code, we'll scrape the page of .pdf extension which is rendered by the default PDF Rewriter (page2fo.xsl), then further append the backcover page to the page2fo.xsl result. The final merged result will be the page2fo.xsl output (more details refer to a previous post) appended by a backcover PDF. The custom JSP that does the merging should be named download.pdf.jsp according to sling resolution rule illustrated in the image below. This JSP will render page request with .download.pdf extension and this JSP file should be placed under the directory where the content node's sling:resourceType is pointing to. The following snapshot shows what to look for such directory to place your custom JSP file (download.pdf.jsp) Basically, it is the value of sling:resourceType property of a content node's jcr:content. In my example, I placed download.pdf.jsp under <company>/components/standardPage directory. 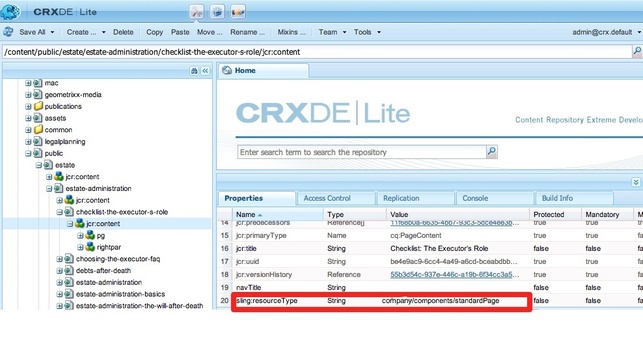 As a result, an user request to http://<host>:<port>.../estate-administration/checklist-the-executor-s-role.pdf will return PDF without the backcover appended, whereas an user request to http://<host>:<port>.../estate-administration/checklist-the-executor-s-role.download.pdf will return you a pdf with a backcover appended. Now, let's take a look at what's in download.pdf.jsp file: <%@include file="/libs/foundation/global.jsp"%> [1] JSP response mime type [2] username and password required to scrap the page with .pdf extension. You can consider to create a dummy user with the least privilege granted rather than using the admin user. [3] Encode username and pwd to be passed to the HTTP server. [4] Derive the page url to scrape from. Such url should have '.download.' replaced with '.' [5] Scrape the .pdf generated by the PDF Rewriter (page2fo.xsl). [6] Read in the backcover PDF from the DAM assuming it is already in the DAM. [7] The output stream the merged document will go to. [8] PDFBox's PDFMergerUtility is the easiest way to merge PDFs. [9] Result goes out to output stream. No code after this line will be reachable. troubleshootingIf an user request to http://<host>:<port>.../estate-administration/checklist-the-executor-s-role.download.pdf gave you blank page, it implies some error has occurred. Check the CQ log under your installation directory. It could be the user in the above [2] does not exist in your CQ, or the required PDFBox library bundle is not installed in your CQ. next upreferences
0 Comments
Leave a Reply. |
Categories
All
Archives
May 2020
|
 RSS Feed
RSS Feed
in loving memory of my mother and my 4th aunt